





一、引言
随着大数据时代的来临,实时计算引擎在数据处理和分析领域扮演着越来越重要的角色,为了帮助初学者和进阶用户更好地了解、对比并选择合适的实时计算引擎,本文将提供详细的步骤指南,通过本文,您将了解到实时计算引擎的基本概念、主流产品对比以及如何使用它们完成任务。
二、了解实时计算引擎
实时计算引擎是一种用于处理和分析实时数据流的技术组件,它能够快速处理大量数据,并产生即时结果,这对于需要快速响应的业务场景至关重要,如金融交易分析、物联网数据处理等。
三、主流实时计算引擎简介与对比
1、Apache Flink
Apache Flink 是一个开源的流处理框架,适用于有界和无界数据流的处理,它提供了高性能、高可扩展性和高容错性,Flink 支持多种编程语言,如 Java、Scala 和 Python。
2、Apache Beam
Apache Beam 是 Google 开发的开源数据流处理框架,旨在简化大数据处理,Beam 支持批处理和流处理,并提供了统一的编程模型,它支持多种语言和平台。
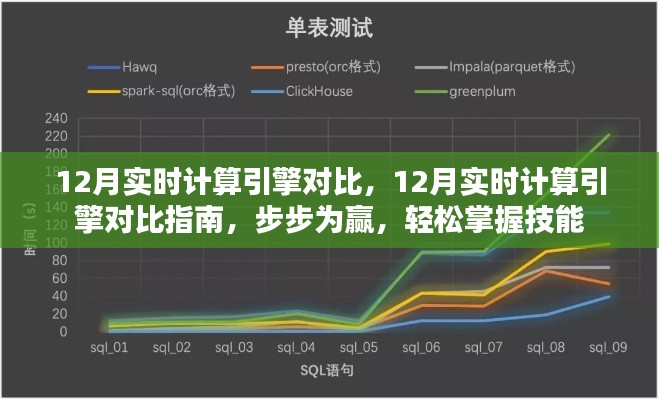
3、Apache Spark Streaming
Spark Streaming 是 Apache Spark 的扩展库,用于处理实时数据流,它提供了高吞吐量和容错性,并支持多种数据源和输出目标,Spark Streaming 更侧重于批处理与流处理的结合。
对比这些实时计算引擎,它们各有优势:Flink 适用于需要低延迟的流处理场景;Beam 提供了统一的编程模型,适合跨平台处理;Spark Streaming 在批处理和流处理的结合上表现优秀,读者可以根据自己的需求选择合适的引擎。
四、选择实时计算引擎的步骤
1、明确需求:确定您的应用场景是批处理还是流处理,以及是否需要即时响应。
2、性能考量:评估不同引擎的性能指标,如吞吐量、延迟和可扩展性。
3、技术栈匹配:根据您的团队技能和现有技术栈选择合适的引擎。
4、社区与生态:考虑引擎的社区活跃度和生态系统,以便获得支持和集成其他工具。
五、使用实时计算引擎完成任务(以 Apache Flink 为例)
1、环境搭建:安装 Java 并下载 Apache Flink,根据您的需求设置集群环境或本地环境。
2、数据准备:准备输入数据,可以是文件、数据库或其他数据源,确保数据格式符合 Flink 的要求。
3、编写程序:使用 Flink 提供的 API 编写程序来处理数据流,使用 DataStream API 处理无界数据流或使用 DataSet API 处理有界数据流。
4、部署与执行:将程序部署到 Flink 集群并启动任务,Flink 会自动进行并行处理和容错处理。
5、结果分析:查看和分析任务结果,根据需要进行调整和优化。
六、进阶学习
完成基本任务后,您可以进一步学习如何优化 Flink 任务、集成其他工具和框架(如 Kafka、Elasticsearch 等),以及深入了解 Flink 的高级功能(如状态管理、连接器等)。
七、总结
本文为您提供了关于实时计算引擎的详细对比指南,包括主流产品的简介和对比、选择步骤以及使用示例(以 Apache Flink 为例),希望本文能帮助初学者和进阶用户更好地了解实时计算引擎,并选择合适的工具完成任务,随着技术的不断发展,实时计算引擎将在未来发挥更大的作用,让我们紧跟时代步伐,掌握这项技能!
转载请注明来自昆山钻恒电子科技有限公司,本文标题:《实时计算引擎对比指南,掌握技能,步步为赢(12月版)》




 苏ICP备18000538号-1
苏ICP备18000538号-1
还没有评论,来说两句吧...